
The easiest way to run Restate is with Restate Cloud.
Keep deploying your code the same way you do now.
Restate Cloud handles resilience, observability, and scalability for your code, with no additional infrastructure to manage beyond your services.
Pair Restate Cloud with a serverless compute provider for the simplest operational experience.
Pre-requisites
You can deploy Restate on any platform that meets the following requirements:- Compute: a runtime environment where you can run the Restate Docker container or binary.
- A persistent volume attached to store Restate’s state. Recommended for cluster deployments. Required for single-node deployments.
- (For clustered setups) An object store to store snapshots.
Compute
The easiest way to deploy and manage a Restate cluster and containerized Restate services is via the Kubernetes operator, as it provides the simplest experience for deploying Restate clusters, deploying services while managing versioning, and more. Therefore, we recommend using the Restate Kubernetes Operator in combination with a managed Kubernetes provider such as AWS EKS, Azure’s AKS, or Google’s GKE. This approach is great even for single-node Restate deployments because it makes managing the Restate node much simpler, handling node restarts or Restate version updates with ease. Kubernetes is responsible for keeping the Restate container running and, crucially, makes sure that the persistent volume attachment follows it around if it moves between nodes.Persistent volumes
Restate is a stateful system that persists data to disk via its embedded state store. Restate stores its state by default in therestate-data directory in the location where the Restate binary gets executed.
To ensure durability, it is essential to use a persistent volume to back this directory.
If you run Restate as a single node, then the durability of the disk defines how durable Restate is.
Therefore, having a persistent volume is required for single-node deployments.
Additionally, you might want to take periodic backups of the persistent volume (see data backups).
In clustered deployments, Restate nodes can failover to other nodes and restore from snapshots stored in an object store.
But each Restate node still benefits from having a persistent volume to store its local state during normal operation.
Mainly because this makes failover much faster, without the need to recompose all state from object store and other nodes.
What does Restate store?
What does Restate store?
Restate has a layered architecture with the following stateful components: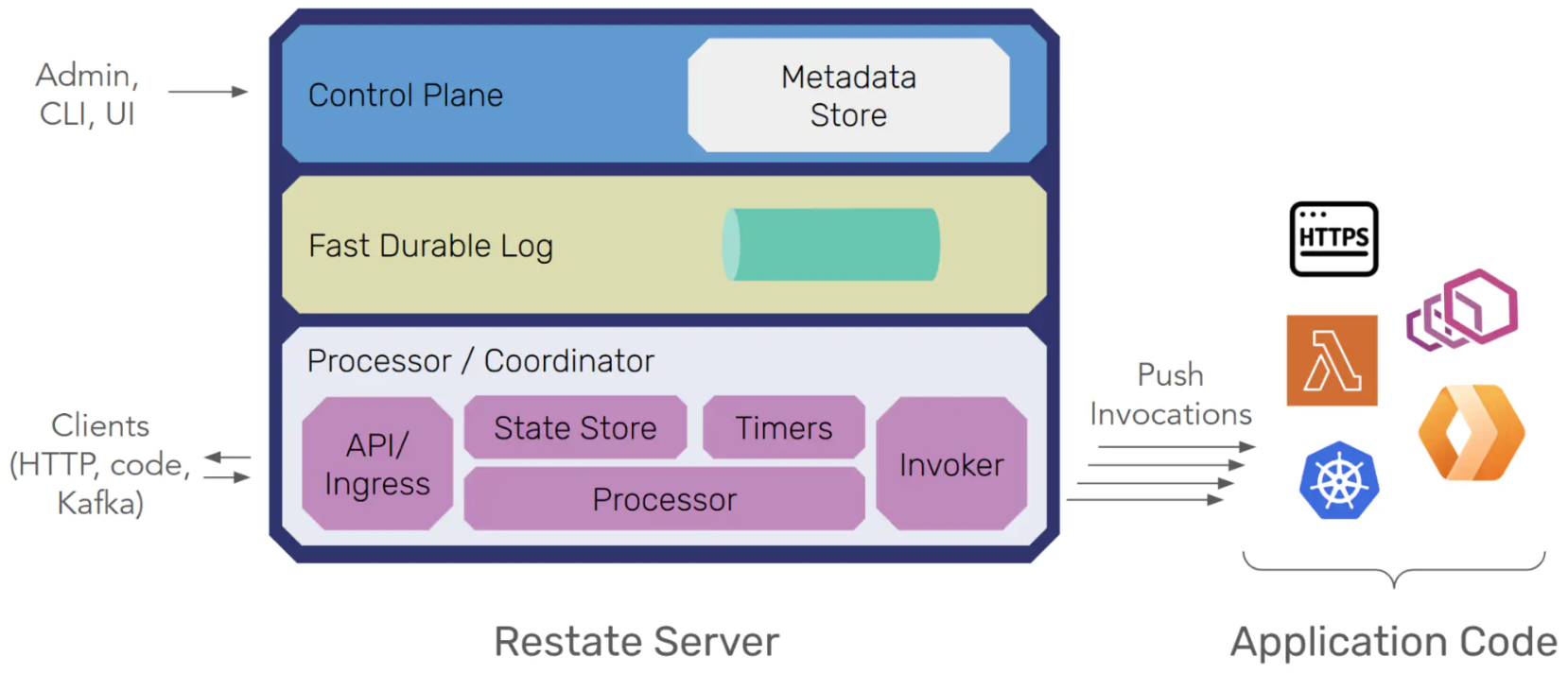
- The metadata store: Restate’s control plane includes a built-in Raft-based metadata store. This store keeps track of the cluster configuration, partition assignments, and other critical metadata. It is essential to the correctness of the overall system.
- The durable log: The log is the primary durability layer. New events (invocations, journal entries, state updates, …) are first persisted in the log, and then move to the partition processors. The log is stored on disk and replicated. Durability is critical here.
- The partition processor stores: The partition processor leader maintains a full cache of the partition’s materialized state in RocksDB for fast reads and updates during execution. This cache can always be rebuilt from the log, so durability is not critical here. In cluster deployments, the content of RocksDB should be periodically snapshotted to an object store, for faster failover.
Object storage for snapshots
Snapshotting Restate partition processors is necessary when running multi-node clusters. Partition snapshots are required to enable log trimming and avoid long catch-up delays when handing over partitions between nodes. Restate supports snapshotting to object stores because they offer great scalability, durability, and cost and are available in all cloud providers and most on-prem setups. Performance requirements for snapshot storage are minimal. Snapshots typically occur only a few times per hour and are read rarely, so the snapshot destination’s performance doesn’t affect cluster performance. See the snapshot documentation for more information.It is also possible to use an object store for metadata storage, removing the need to run the stateful metadata-server role on some or all cluster nodes. However, this feature is only tested and supported on Amazon S3 at present, and it requires nodes to have low-latency access to the object storage service.
This is currently only offered by AWS S3.
Supported Object Stores
Currently we support the following object stores:- AWS S3
- MinIO (only for snapshots, not metadata)
- Coming soon: Google Cloud Storage and Azure Blob Storage (Contact us for more info: Discord/Slack)
Single-Node vs. Cluster Deployments
Restate can be deployed as a single-node setup or as a distributed cluster, depending on your requirements for availability and scalability.| Requirement | Single-Node | Cluster |
|---|---|---|
| Durability | OK (when using durable disk) | Better |
| High Availability | ❌ | ✅ |
| Geo-replication | ❌ | ✅ |
| Horizontal Scaling | ❌ | ✅ |
| Vertical Scaling | ✅ | ✅ |
When to Choose Single-Node
Single-node Restate runs as a single binary that persists data to disk. To ensure durability, it is essential to use a persistent volume for storing all Restate data. Despite being a single-node setup, this setup does not sacrifice durability. Restate fsyncs committed data to disk before acknowledging network messages, providing the highest level of durability. The durability of the underlying disk storage determines how durable Restate is. In case of a node or Restate process crash, you won’t lose data, but you will experience a short window of unavailability while the process restarts. Use this for: development, testing, or production workloads which can tolerate short downtimes and do not require high throughput (horizontal scaling).When to use Cluster Deployments
Restate cluster deployments serve multiple purposes:- High-availability: In case of a crash, other nodes of the cluster can take over immediately, rather than waiting on the failed node to get rescheduled.
- Geo-replication: To reduce the risk of downtime even further, Restate clusters can run in a geo-replicated setup, with nodes deployed across multiple availability zones or even regions. Depending on your architecture, such a deployment allows you to remain available through outages affecting entire zones and even regions.
- Scalability by spreading load over multiple nodes.
- Even better durability, by persisting copies of the data across multiple zones / regions.
Platform-Specific Deployment Guides
Follow the links below for platform-specific deployment instructions:- Kubernetes: Recommended for production deployments, in combination with a managed Kubernetes provider from your cloud provider.
- Cloud Providers:
- Docker: For local development and testing. More involved to run in production.